Log10 aims to boost your LLM's output accuracy 🌐
Plus: CEO Arjun on LLMOps, ML stack, and Log10's goals...
Published 30 Apr 2024CV Deep Dive
Today, we’re talking with Arjun Bansal, Co-Founder and CEO of Log10.
Log10 is an LLMOps platform that places a heavy emphasis on measuring and improving the accuracy of your LLM’s output - using data from your prompts, the completion and any other system feedback. Founded by Arjun and co-founder Niklas Nielsen in 2023, the startup is hyper-focussed on delivering value to customers across engineering and product teams looking to optimize their LLM outputs, and fits above the foundational model providers like OpenAI and Anthropic.
Log10 currently has 100s of organizations using the platform, who come from companies such as Echo AI, OpenBB, Lime, Doppler and Pendium. The team also has an impressive combined 27+ years in AI, at companies such as Nervana (Arjun’s first company, acquired by Intel), Intel (where Arjun led the AI software and research group) and MosaicML (where Niklas was the Head of Product). Last week, the startup announced a $7.2m seed round raise led by TQ Ventures and Quiet Capital, with participation from Essence Venture Capital.
In this conversation, Arjun walks us through the founding premise of Log10, why LLMOps is so critical to a healthy ML stack, and his goals for the company in the next 12 months.
Let’s dive in ⚡️
Read time: 8 mins
Our Chat with Arjun 💬
Arjun - welcome to Cerebral Valley! First off, give us a bit about your background and what led you to co-found Log10.
Hey there – I’m Arjun, Co-Founder and CEO of Log10. I've been working in the AI space for over 20 years, starting with academic training at places such as Caltech, Brown and Harvard all the way to postdoctoral work in computational neuroscience, and then moving into industry. Log10 is my third AI startup. I started an AI hardware company called Nervana Systems that was acquired by Intel, and then I went on to lead Intel's AI software and research group – which is where my co-founder Nik and I worked quite closely. Nik comes from a distributed systems background – he has a lot of experience in the AI software infrastructure space -- specifically, training large models -- and most recently he was Head of Product at Mosaic ML.
We got together a year ago, when we started noticing the strand of developers wanting to build applications on top of ChatGPT. We realized firsthand that it was really hard to get these models to behave in the ways that we wanted them to behave, and to get the kind of accuracy that one would want for your applications. That's when we started with Log10 - focussing on the question ‘How do we help developers and enterprises get the best accuracy out of their LLM-based applications so they can deliver exceptional customer experiences?’
Give us a top-level overview of Log10 - how would you describe it to the uninitiated developer or ML team?
Log10 is an LLMOps platform. We observe the calls that are going from your application to an LLM and seamlessly improve the LLM app’s accuracy using the best data that we have available – which could be the prompt, the completion, as well as any kind of feedback that's part of that system.
At a high level, we fit above the foundational model providers like OpenAI and Anthropic. We also support Gemini, Mistral, self-hosted models and open-source models – we sit in between those models and the end-user LLM application.
Who are your users today? Who’s finding the most value in what you’re building with Log10?
Today, our user base is quite broad – we serve developers and product managers, as well as GMs in charge of building any LLM-powered feature or product for their company. We also serve the developers or data scientists charged with implementing that feature.
Ultimately, our target audience are folks who have ownership over delivering on the business goal that the feature or the product is trying to achieve – they’ve felt the pain of running into accuracy issues like hallucinations or inaccurate outputs after deploying based on a demo. That's where Log10 can come in and, through a very seamless integration, start delivering on improving the accuracy of the LLM apps.
Any customer success stories that you would like to share, to help illustrate the impact that Log10 is having on your customers?
We've published about our work with Echo AI, who was one of our first customers. They've scaled to over 15 million logs at this point. They provide a service that can ingest transcripts from contact centers and provide analytics on top of that, to help their customers figure out how those conversations have been going, and rate the call center agents. They’ve been using us throughout their pipeline -- everything from logging and debugging errant LLM calls, to improving the accuracy of their applications. We showed that through our accuracy improvement techniques, we could improve the accuracy of one of their use cases by 20 F1 points.
Another surprising thing was I got a call from a Head of Finance and he said, “Log10 saved us 40% on our LLM costs because we realized a few issues with how we were calling LLMs and logging them”. Saving 40% on a pretty big cost number is great to hear because cost hadn't really been a focus for us, but they've been using us in this surprising way.
What sets Log10 apart from others in the LLMOps space? What’s unique about the technical approach you’re taking?
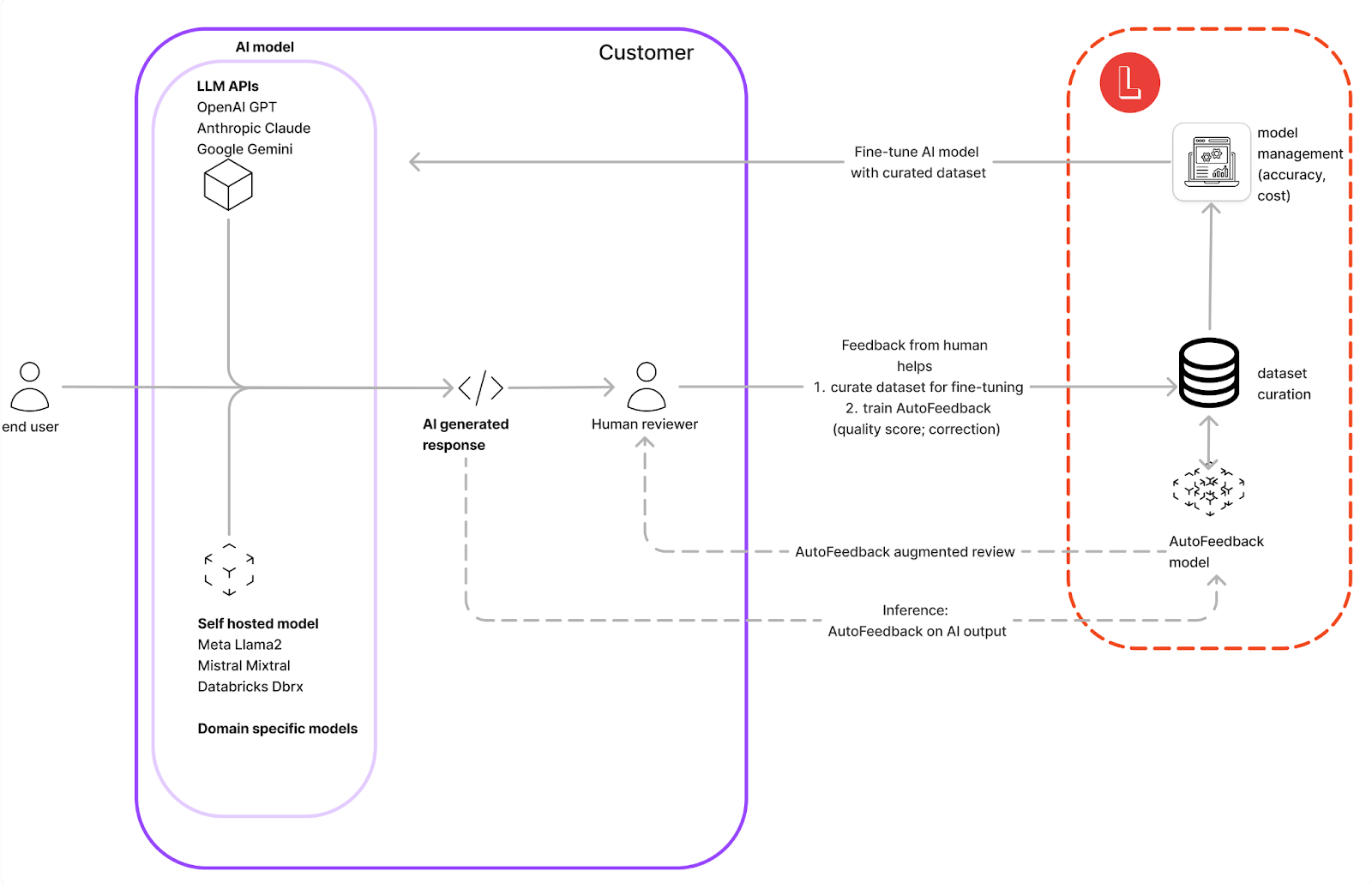
We've been hyper-focused on not just measuring accuracy, but actually closing the loop with improving accuracy as well. We've done a couple of things to serve this - one is actually using AI to improve the LLM apps that people are building, and the second is providing a very seamless experience for developers.
On the AI side, we realized that the human perspective was going to be key to improving LLM applications. Out-of-the-box models are not good enough at mimicking human reviewers because they tend to be biased. Therefore, getting human feedback tends to be the gold standard and inevitably, the long pole in the tent in terms of deploying these applications to production. We asked: what if we could build these LLM apps in a way where it becomes 10x cheaper, 100x faster, and 1000x more scalable than having to go out and hire human reviewers to get the labeled human feedback?
So, what we’ve built is an AutoFeedback system which uses a combination of synthetic data and fine-tuning to mimic the performance of human reviewers. We showed a 44% improvement in evaluation accuracy through a combination of synthetic data and fine-tuning, and we published that in a technical report that's on our blog.
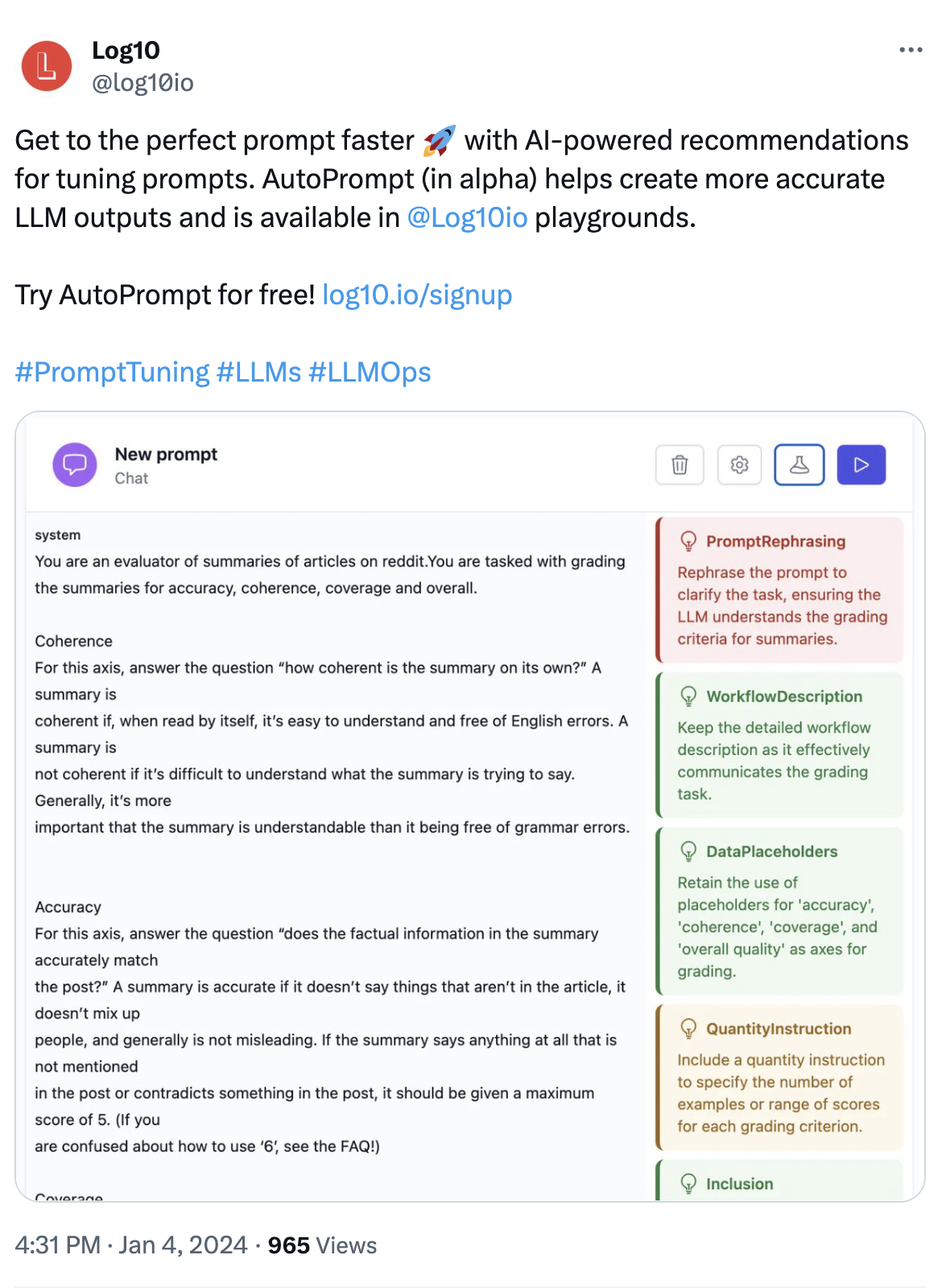
We found that people can use our AutoFeedback models in a few different ways. They can triage the LLM output that goes out to human reviewers, or they can set up monitoring alerts based on quality scores. They can also prepare datasets and improve the accuracy of the underlying model via prompt optimization or fine-tuning. Another distinct thing that we've built is being able to serve up these models in a low-latency way: we're minimizing overhead if it's being deployed in a real time setting.
On the developer experience front, we have a one-line, proxi-less integration into a variety of LLM provider libraries such as OpenAI, Anthropic, Gemini, Mistral, Together, Lamini and MosaicML, and support lightweight agentic frameworks such as Magentic in addition to Langchain. There is technical complexity to supporting these model abstractions robustly with the ever expanding feature sets such as async, streaming and tool use which we manage on behalf of our users. We’ve recently released further accuracy improvement tooling that makes it very easy to generate a cost, latency and accuracy report across multiple providers, as well as to get prompt optimization suggestions.
The last 12-18 months have been hugely transformative in the AI space. How has the advent of generative AI and widespread LLM adoption impacted the way you’re thinking about LLMOps with Log10?
Before, you used to collect a large data set and had to have an ML team and a data scientist team before you got anywhere close to deploying these LLM applications. The magic of LLMs has been that you can just start a prompt and anybody with non-coding or non-ML experience can deploy these models. The great thing is how much things have become democratized – that said, it's come at the expense of not knowing up-front what your validation accuracy is. Previously, through the data set that you collected, you would have a notion of what your validation accuracy was going to look like once you deployed.
In my opinion, this is what has called for a radically different approach to doing LLMOps and evals and feedback – that is, measuring and improving accuracy in production once the model is deployed. The job to be done by a product like ours is understanding how to make that experience seamless – collecting all of that data and then using it to improve the accuracy of the overall LLM application. Some of those steps come later in the flow compared to where they used to before.
What’s the hardest technical challenge around building Log10 into a player in the LLMOps space?
There have been a few. Obviously, controlling and steering these models is still a bit of an open question - you have companies like Anthropic investing heavily into mechanistic interpretability research but it tends to be on the benchmarks that go into the eval suite for the base models like Claude. That said, every use-case that a company has tends to be different from what was in the benchmark, and so the challenge is getting really good at understanding the model at its core. Enabling the mechanistic interpretability approach for each use case is something that's needed, and that's something we've been going after with our research program.
Similarly, on the engineering side, there are challenges around how to manage LLMs at scale for doing accuracy analysis with asynchronous streaming setups, where you're piping the output from one model to another to minimize latency. Those have been some of our key technical challenges.
What are your key areas of focus for the next 6-12 months?
Given where the product is today, we’re going to be focusing more on how to take the output of the AutoFeedback model and use it to improve the quality of the underlying model through techniques such as DPO and RLHF. We’re also pushing in this direction of accuracy, but finding the Pareto frontier with cost, which is becoming more important as companies scale to millions of calls per week. So, helping companies manage that accuracy versus cost balance without having to do the work themselves is another frontier we're focussed on.
Overall, as our platform gets better at handling more use cases, the core AI algorithms will keep improving as well – so there's this meta improvement happening.
Share a little bit about your culture - what do you look for in prospective hires?
Firstly, we’re very customer-obsessed. As a company, we really go into the details of what developers want and try to match their needs, whilst keeping up with the needs of their organization – what do they need to be successful in terms of delivering to their customers? We’ve conducted user research across 200+ companies and found that the majority consider accuracy as central to serving their customers – and so we've been really focused on AI accuracy ourselves.
Team-wise, we have a bunch of open roles across the board – everything from AI researchers to data scientists, as well as ML engineering and full-stack engineering. In general, we’re looking for people with a growth mindset, who are curious and invigorated by learning new things every day. We are uniquely tackling the challenges around understanding large models at a fundamental level to make them usable for end user applications by building a team with a diverse array of backgrounds.
Anything else you want people to know or understand about Log10?
We'd encourage everybody to give us a try. We have a self-serve version of the platform that has up to 1 million logs free, as well as unlimited collaborators so that people can try it out with their teams. Compared to some of the other products in the market, we drive a lot of value: we benchmarked ourselves on pricing and offer a service that's up to 200x more storage in a free tier, up to 25x cheaper on storage, no additional per-user fees, no max limits on storage and so much more. There are a number of pricing features where we're far more generous compared to where the competition is.
The other big thing is that, as part of this release, we’re opening up the waitlist for our AutoFeedback feature. This is one of the main ways in which we've been driving accuracy for customers, and we’d love for people to sign up for AutoFeedback and share the tasks they’re giving human reviewers today that they’d like automated.. We’re looking forward to helping them out!
Conclusion
To stay up to date on the latest with Log10, follow them on X or LinkedIn and learn more about them at Log10.io.
Read our past few Deep Dives below:
If you would like us to ‘Deep Dive’ a founder, team or product launch, please reply to this email (newsletter@cerebralvalley.ai) or DM us on Twitter or LinkedIn.
Join Slack | All Events | Jobs