Gradient is Accelerating AI Adoption in Enterprise 📈
Plus: Co-founder & CEO Christopher on AI agents, LLMs and RAG...
Published 16 Apr 2024CV Deep Dive
Today, we’re talking with Christopher Chang, Co-Founder and CEO of Gradient.
Gradient is a consolidated platform providing compute infrastructure, tuned models and internal tooling for enterprises. Its stated mission is to accelerate the adoption of AI in the enterprise, by helping internal teams leverage AI for automating any sort of enterprise workload. Chris co-founded the company alongside Mark Huang and Forrest Moret, and previous to Gradient, the founding team built AI products at Big Tech companies including Google, Netflix and Splunk.
Gradient’s target audience are operational leaders and the technical teams supporting them, that are working on automation systems or operational tooling. They work with a wide range of enterprise organizations, including Netflix, Corewell Health, UC Berkeley, and Boeing just to name a few. In October 2023, the startup launched out of stealth and announced $10 million in funding led by Wing VC with participation from Mango Capital, Tokyo Black, The New Normal Fund, Secure Octane and Global Founders Capital.
In this conversation, Chris walks us through the founding premise of Gradient, why agents are the future of the enterprise AI stack, and his goals for the next 12 months.
Let’s dive in ⚡️
Read time: 8 mins
Our Chat with Chris 💬
Chris - welcome to Cerebral Valley. First off, share a bit about your background and what led you to co-found Gradient.
Hey there! I’m Chris, the CEO of Gradient, and I primarily come from an AI/ML product background. Most recently, I was running the AI studio group at Netflix, where we were deploying AI to solve content production challenges across the entire lifecycle of Netflix's original content. There, I was actually working on a lot of projects with early Transformer models, but back in 2021, AI/ML was still much better for predictive analysis than any actual content generation or subjective work.
Over time, it became really clear to me that a lot of the transformative value in generative AI would actually cause us to rethink how to solve these kinds of operational problems across large enterprises. So, that's how we ended up starting Gradient - to try to solve and accelerate that AI adoption for a much broader enterprise group.
Give us a top-level overview of what Gradient is, for those who aren’t as familiar.
At Gradient, we accelerate AI adoption in enterprise. We do this by providing the most comprehensive solution for AI transformation via something we call the Gradient AI Foundry. Within the Gradient AI Foundry, our customers have access to a compute infrastructure, domain and task-specific models and tooling required for a company to be able to leverage AI for automating any sort of enterprise workload.
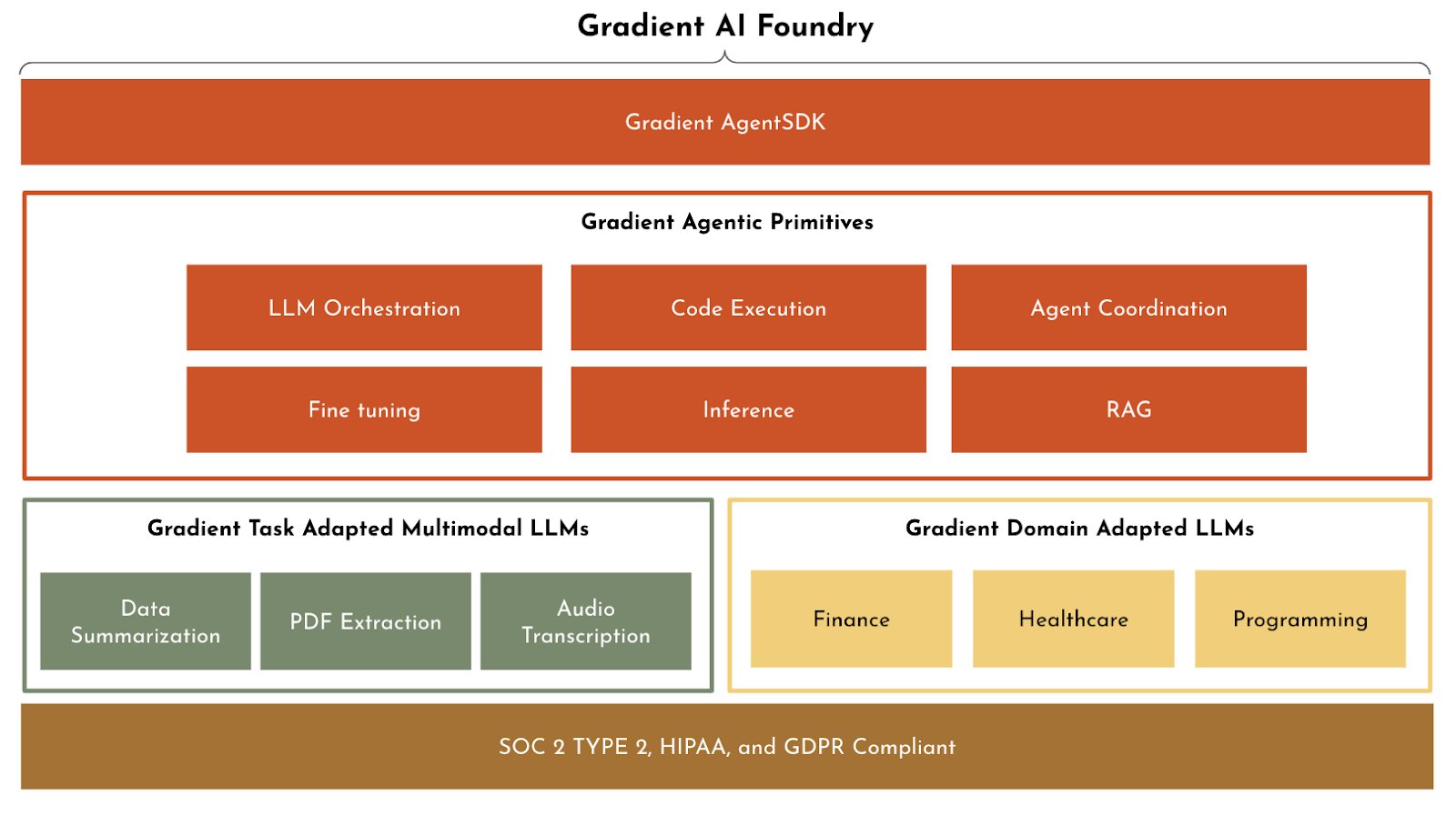
I would describe our space as what I call ‘operational enterprise workloads’ - and our target demographic are operational leaders and the technical teams supporting them that are working on automation systems or operational tooling. Usually, what they're trying to do is solve some sort of business process with an internal tool, and increasingly are looking to deploy an AI native solution instead of a tooling product. This is the kind of demographic that we play into.
What types of use-cases are you seeing success with early on? Who are your most engaged users?
We’re definitely suited to industries that are operationally heavy. For example, the financial services sector has very heavy regulatory requirements, including a lot of paper processing. We've helped companies deploy solutions like KYC compliance, customer service automation and SEC regulatory compliance for their marketing materials and investor communications. Typically, these kinds of tasks are all done either by knowledge workers alone, or by knowledge workers with internal tooling - and we've been able to alleviate all of that with a fully-automated AI solution.
In that sense, we have a couple verticals where we specialize - for example, healthcare and financial services, but we also work with operational teams at a large number of other enterprises as well. The core problem in enterprise today is that we've got these AI models that are very smart, but lack experience. When we say experience, this specifically relates to having the domain-specific context to be able to perform tasks - so, that enterprise data is critical in terms of being able to grant AI the capability to perform a task as well as a typical knowledge worker in the company.
That’s why domain and task-specific models have played such a critical role in unlocking what’s possible for enterprise organizations in these unique industries.
It seems like every enterprise has to make a security-driven choice between using open-source models like Mixtral, and closed-source ones like GPT-4. How are you thinking about this internally at Gradient?
Great question. There's one core constraint that will determine whether a company is willing to work with OpenAI or any other proprietary models, and that is: security concerns around infusion or private knowledge.
The more privacy-sensitive the company is, the more likely that they are going to focus on models they can deploy on-prem or in their own VPC, in a dedicated environment that they know is strictly controlled by their privacy and security restrictions. So in that world, we found that LLama 2 and Mixtral models are typically the popular models of choice.
In the other world, where companies are more comfortable with cloud and managed services, we'll complement the OpenAI ecosystem, which is of course the natural model of choice. We’ll then add specialized models that are either more efficient for repetitive high volume tasks, or specialized models for a particular task that can outperform in that company-specific context.
There are a number of teams approaching the problem space of helping enterprises fine-tune and deploy AI models. What is unique about the approach that you’re taking at Gradient?
Our strategy is to focus on the enterprise and the operational or business problem first, and then build out the platform that can solve that problem comprehensively. That strategy is different from what I would call the ‘traditional’ LLMOps stack. When it comes to fine-tuning or RAG development, companies usually focus on an individual piece as they're selling to an AI team - in our position, we're selling to the business user and the technical team that's supporting them.
This makes it different operating in that world, because our customers are looking to have AI/ML as an abstraction or an integration via an API, versus wanting to go in themselves and fiddle with all the knobs themselves - which you would traditionally do if you were an ML engineer at Pinterest, for example, instead of at a company like PNC Bank.
Any successful customer stories you’d like to share?
Absolutely. One of the key challenges with larger institutions is they have a lot of data that is in a myriad of state and format. At Gradient, what we've done is consolidated that data and made it easily accessible to the AI system, by providing simpler levels of abstraction to manage the RAG system and the fine-tuning platform. We've added enterprise features like synthetic data generation and simpler fine-tuning and instruction-tuning to improve the alignment of the model, without the user having to invest too much time into that process.
I’ll give a concrete example of how this has worked for one of our customers - a financial institution we’re working with to implement SEC and AML compliance. All of their data was in PDF format and other unstructured data formats - what we did was combine our AI powered data processing platform with Albatross, our finance LLM, to parse and extract that information to evaluate regulatory questions with higher accuracy than they could have ever done otherwise. We have that all bundled as an API call, so that the company can then integrate that directly into their internal tooling without having to manage any of that themselves. That's a core example of what we do.
How are you navigating the immense amounts of regulation and scrutiny that verticals like finance and healthcare come under, especially as it relates to technology and data privacy?
The two elements to think about here are security, and then accuracy / quality. On the security side, we're SOC 2 Type 2, HIPAA, and GDPR compliant, and we've designed our platform to be flexible in terms of where we’re able to integrate our services - either as dedicated deployments ourselves, or within a user's VPC. This is critical to us because user data is gold with enterprises, and even if you're not in these heavily-regulated industries, there’s currently a lot of concern around private data being commercialized irresponsibly. So, we found it to be an advantage to focus on this security piece first.
The second element is around accuracy and quality. When you're working in a field like healthcare and explaining your medical benefits to patients, you don't want to risk having any sort of misinformation included in the communication. We try very hard to improve the model’s capabilities, for example via active mitigation of hallucination. We also enable our customers to further align the system via fine tuning or DPO via our training platform, and then couple that with managed RAG and an automatically fine-tuned embeddings model to improve the accuracy of the retrieval. Finally, we have a LLM grounding feature that forces the model to review and cite the sources it's using to generate the response. This way, the answer is always grounded in a document that it was able to reference, instead of something that it basically just came up with via hallucination.
You launched out of stealth back in October 2023. How have you kept up with the immense volume of research and product releases since then, and how has this shaped your approach at Gradient?
From a first principles perspective, our approach has always been to assume that most technology will become quickly commoditized. So, we try to keep an eye on which incremental technology makes the most sense for us to invest in. For example, when we started to build out our fine-tuning service, one of our fundamental questions was “how is that space going to evolve, and how do we actually want to apply value?” We opted to adapt open-source frameworks internally and modify them in a modular fashion so that we could still leverage a hybrid approach - using the best of the open source development, but also having the flexibility to further adapt it as we need to for our custom services. The same approach goes for our model development as well.
Every three months, we can assume there's going to be a new model that's better than the last. When we talk about domain adaptation or task adaptation, what's actually important is the data and the training process by which you apply those improvements to these generalist models. Instead of building foundational models from scratch, we really invested a lot in understanding how to tune these models via pre-training, instruction-tuning and DPO to get to the quality of the output that we wanted for our customers. That allows us to plug and play our training process when Llama 3 comes out, for example, and be able to have fine-tuned models that will work even better than before.
Agents play a huge role in Gradient’s long-term vision for the enterprise - could you walk us through what excites you and the team about an AI-agentic future?
I'm personally very excited for agents to become fully productionized, and I think it's going to completely transform the way we think about software in a business setting. Today, the fundamental unit of value in a business is a workflow - which is a human-curated process that has pseudo-structure dictated either by a human or a human with software. But, the workflow tools that are being built today, even the AI-augmented ones, are all basically heuristics that are manually and rigidly defined as product experiences. When we talk about agents, we think software will no longer be deterministic.
With agents, you’re able to actually provide much more rich and dynamic workflows without ever needing to have human intervention take place. If you think about the whole industry around data processing, information processing, and internal tooling, all of that will completely change when agents come into play, because suddenly you won’t need to program these workflows manually anymore. You’ll just provide the agent with objectives and examples, and access to all of the information and tooling to do the work. So, what you're focusing on as an engineer or operator is managing that, observing it, and making sure that it's not going off the rails. I think agents will really overhaul our relationship with software.
This is also why we actually have opted not to build rigid workflow tools on top of our system - because we're actually internally building out an agent-powered workflow automation system that will be able to solve any kind of enterprise problem without a human or UI process for that.
What are your key areas of focus for the next 6-12 months? Anything specific you’re looking to double down on?
The highest-level thing that we are really building towards is our agentic workflow system. We’ve already been doing a lot of testing with GPT-4 and other sophisticated models, and we think that solving enterprise problems is actually getting very close. With LLama 3 and GPT-5 coming in the summer, we're basically expecting this to really ramp up and be able to automate our enterprise solutions.
The second thing we’re looking at is around post-Transformer models, and our emphasis has been extending beyond text-generation or multimodality. We do think this will also transform the way we approach intelligence from an organizational perspective, in terms of business intelligence or operational intelligence. That’s an area that we've been investing more time in as well.
The third and final piece is the interplay of these systems. RAG is actually fairly limited because enterprise work actually requires large amounts of context, and so that's another dimension of value that we're looking into as well, in terms of augmenting existing models and being able to extend them so that they can actually take in large documents, like an SEC 10k. There are certain areas where it's just better to have all of the context available.
Talk to us about the culture you’re working to build at Gradient? Are you hiring, and what do you look for in prospective members joining the team?
There are a couple of externalities that come with the space we’re operating in, and then there’s a way we try to fit that in our own culture. So firstly, our space is always changing, and secondly, we’re in a very technical space given the fact that the key benefactors of our technology are non-technical. Those two externalities require generalists who are highly curious and focused on solving end-user problems well. That’s the kind of person that we optimize for at Gradient - those who think about the whole end-to-end product experience benefiting that non-technical individual.
An important piece is also that because the space is changing so much, you do need to have people who are passionate and intrinsically motivated to keep up and to apply their own knowledge and unique perspective to it. Separately, we also focus on critical thinking and rigor - because the space is evolving, there are a lot of ideas that appear to be valuable that actually aren’t. We focus a lot on hiring people who put a lot of emphasis on first principles thinking and critical rigor to assess whether or not research breakthroughs or customer feedback will actually be valuable for us.
Those are the core tenets of our team, and we think that's going to be the way that we build a differentiated advantage from an organizational perspective.
Conclusion
To stay up to date on the latest with Gradient, follow them on X and learn more at them at Gradient.
Read our past few Deep Dives below:
If you would like us to ‘Deep Dive’ a founder, team or product launch, please reply to this email (newsletter@cerebralvalley.ai) or DM us on Twitter or LinkedIn.
Join Slack | All Events | Jobs | Home